Всем привет! Сегодняшняя статья посвящена тому, как правильно собрать семантическое ядро (СЯ). Если вы занимаетесь SEO-продвижением в Google и Яндекс, хотите увеличить естественный трафик, повысить посещаемость и продажи сайта – этот материал для вас.
Чтобы докопаться до истины, мы изучим тему от «А до Я»:
В заключение рассмотрим общие правила для составления СЯ. Итак, давайте приступим!

Семантическое ядро: что это и какие бывают запросы
Семантическое ядро сайта (известное еще как «смысловое ядро») – это набор слов и словосочетаний, который точно соответствует структуре и тематике ресурса. Проще говоря, это те запросы, по которым пользователи могут найти сайт в Интернете.
Именно правильное семантическое ядро дает поисковым системам и аудитории полную картину об информации, представленной на ресурсе.
Например, если компания продает готовые открытки, то семантическое ядро должно включать такие запросы: «купить открытку», «открытка цена», «открытка на заказ» и подобные. Но не: «как сделать открытку», «открытка своими руками», «самодельные открытки».

Интересно узнать: LSI-копирайтинг. Заменит ли методика SEO?
Классификация запросов по частотности:
- Высокочастотные запросы (ВЧ) – самые часто «забиваемые» в строку поиска (например, «открытка купить»).
- Среднечастотные (СЧ) – менее популярные, чем ВЧ ключи, но также интересующие широкую аудиторию («открытка купить цена»).
- Низкочастотные (НЧ) – словосочетания, которые запрашивают очень редко («купить художественную открытку»).
Важно отметить, что четких, отделяющих ВЧ от СЯ и НЧ, границ не существует, т. к. они варьируются в зависимости от тематики. К примеру, для запроса «оригами», ВЧ показатель 600 тыс. показов в месяц, а для «косметика» – 3,5 млн.
Если обратиться к анатомии ключа, то ВЧ состоит только из тела, СЧ и НЧ дополнены спецификатором и «хвостиком».

При формировании семантического ядра нужно использовать все виды частотности, но в разных пропорциях: минимум ВЧ, максимум НЧ и среднее количество СЧ.
Чтобы стало понятнее, проведем аналогию с деревом. Ствол – это самый главный запрос, на котором все держится. Толстые ветви, расположенные ближе к стволу, – среднечастотные ключи, также пользующиеся популярностью, но не такой, как ВЧ. Тонкие веточки являются низкочастотными словами, которые тоже используются для поиска нужного товара/услуги, но редко.

Разделение ключей по конкурентности:
- высококонкурентные (ВК);
- среднеконкурентные (СК);
- низкоконкурентные (НК).
Данный критерий показывает, сколько веб-ресурсов использует данный запрос для продвижения. Здесь все просто: чем выше конкурентность ключа – тем сложнее пробиться и удержаться с ним в топ-10. Низкоконкурентные также не стоят внимания, так как являются малопулярными в сети. Идеальный вариант – продвигаться по СК запросам, с которыми реально занять первые места в стабильной бизнес-сфере.

Классификация запросов согласно потребностям пользователей:
- Транзакционные – ключи, связанные с действием (купить, продать, загрузить, скачать).
- Информационные – для получения каких-либо сведений (что, как, почему, сколько).
- Навигационные – помогают найти информацию на конкретном ресурсе («купить телефон розетка»).
Остальные ключевики, когда сложно понять намерение пользователя, относят в группу «Прочие» (например, просто слово «открытка» вызывает массу вопросов: «Купить? Сделать? Нарисовать?»).

Зачем сайту нужно семантическое ядро?
Сбор семантического ядра – это кропотливый труд, требующий много времени, сил и терпения. Составить правильное СЯ, которое будет работать, в «два счета» не получится.
Здесь возникает вполне резонный вопрос: стоит ли вообще тратить усилия на подбор семантического ядра для сайта? Если вы хотите, чтобы ваш интернет-проект пользовался популярностью, постоянно увеличивал клиентскую базу и, соответственно, повышал прибыль компании, – ответ однозначный: «ДА».
Потому что сбор семантического ядра помогает:
- Повысить видимость веб-ресурса . Поисковики Яндекс, Google и другие будут находить ваш сайт по выбранным вами ключам и предлагать его пользователям, которые интересуются данными запросами. Как результат – приток потенциальных клиентов растет, а шансы продать товар/услугу увеличиваются.
- Избежать ошибок конкурентов. При создании СЯ обязательно выполняется анализ семантического ядра конкурентов, занимающих первый позиции в поисковой выдаче. Благодаря изучению сайтов-лидеров, вы сможете определить, какие запросы помогают им держаться в топе, на какие темы они пишут тексты, какие идеи являются неудачными. В ходе анализа конкурентов также могут возникнуть идеи относительно того, как развить именно свой бизнес.
- Сделать структуру сайта . Семантическое ядро советуют использовать как «помощника» для создания структуры сайта. Собрав полное СЯ, можно увидеть все запросы, которые вводят пользователи при поиске вашего товара или услуги. Это поможет определиться с основными разделами ресурса. Скорее всего, вам нужно будет сделать такие страницы, о которых изначально вы даже и не думали. Важно понимать, что СЯ только подсказывает интересы пользователей. В идеале, структура сайта соответствует бизнес-сфере и содержит контент, удовлетворяющий потребности аудитории.
- Исключить переспам. После анализа семантического ядра сайтов-конкурентов из топа, вы сможете установить оптимальную частотность ключевиков. Потому что нет универсального показателя плотности запросов для всех страниц ресурса, а все зависит от тематики и типа страницы, а также языка и самого ключа.
Как еще можно использовать семантическое ядро? Для составления правильного контент-плана . Грамотно собранные ключи подскажут темы для текстов и постов, которые интересуют вашу целевую аудиторию.
Вывод . Без СЯ создать интересный, популярный и рентабельный интернет-проект практически НЕВОЗМОЖНО.
Материал в тему:

Подготовка к сбору семантического ядра для сайта
Перед тем как создать семантическое ядро сайта, нужно выполнить следующие действия:
I. Изучить деятельность компании («мозговой штурм»)
Здесь важно выписать ВСЕ услуги и товары, которые предлагает организация. Например, чтобы собрать семантическое ядро для интернет-магазина мебели, можно использовать такие запросы: диван, кресло, кровать, прихожая, тумба + реставрация, ремонт. Здесь главное – ничего не упустить и не добавить лишнего. Только актуальная информация, т.е. если компания не продает пуфы и не ремонтирует мебель, эти запросы не нужны.

Кроме мозгового штурма, можно воспользоваться сервисами Google Analytics и Yandex.Metrika (рис. 1) или личными кабинетами в Google Search Console и Вебмастер Яндекс (рис. 2). Они подскажут, какие запросы наиболее популярны у вашей целевой аудитории. Такая помощь доступна только уже работающим сайтам.
Тексты в помощь:

- Advego – работает по такому же принципу, как и Istio.com.

- Simple SEO Tools – бесплатный сервис для SEO-анализа сайта, в том числе и семантического ядра.

- Lenartools. Работает просто: загружаете страницы, откуда нужно «вытянуть» ключи (max 200), кликаете «Поехали» – и получаете список слов, которые чаще всего используются на ресурсах.

II. Для анализа семантического ядра сайта-конкурента:
- SEMRUSH – нужно добавить адрес ресурса, выбрать страну, нажать «Start Now» и получить анализ. Сервис платный, но при регистрации предоставляется 10 бесплатных проверок. Подходит также для сбора ключей для собственного бизнес-проекта.

- Searchmetrics – очень удобный инструмент, но платный и на английском языке, поэтому доступен не всем.

- SpyWords – сервис для анализа деятельности конкурента: бюджет, поисковый трафик, объявления, запросы. В бесплатном доступе «урезанный» набор функций, а за отдельную плату можно получить детализированную картинку о продвижении интересующей компании.

- Serpstat – многофункциональная платформа, которая предоставляет отчет о ключевиках, рейтинге, конкурентах в поисковой выдаче Google и Yandex, обратных ссылках и др. Подходит для подбора СЯ и анализа своего ресурса. Единственный минус – полный спектр услуг доступен после оплаты тарифного плана.

- PR-CY – бесплатная программа для анализа семантического ядра, юзабилити, мобильной оптимизации, ссылочной массы и многого другого.

Еще один эффективный способ расширения семантического ядра – использовать синонимы. Пользователи по-разному могут искать один и тот же товар или услугу, поэтому важно включить в СЯ все альтернативные ключи. В поиске синонимов помогут подсказки в Google и Яндекс.

Совет . Если сайт информационный, сначала нужно подобрать запросы, которые являются главными для данного ресурса и по которым планируется продвижение. А затем – сезонные. Например, для веб-проекта о модных тенденциях в одежде ключевыми будут запросы: мода, женская, мужская, детская. А, так сказать, «сезонными» – осень, зима, весна и др.

Как собрать семантическое ядро: подробная инструкция
Определившись со списком запросов для вашего сайта, можно приступать к сбору семантического ядра.
Это можно сделать:
I. БЕСПЛАТНО, используя:
Wordstat Yandex
Яндекс Вордстат – очень популярный онлайн-сервис, с помощью которого можно:
- собрать семантическое ядро сайта со статистикой за месяц;
- получить похожие к запросу слова;
- отфильтровать ключевики, вводимые из мобильных устройств;
- узнать статистику по городам и регионам;
- определить сезонные колебания ключей.

Большой недостаток: «выгружать» ключи придется вручную. Но если установить расширение Yandex Wordstat Assistant, работа с семантическим ядром ускорится в разы (актуально для браузера Opera).
Пользоваться просто: нажимаем на «+» возле нужного ключа или кликаем «добавить все». Запросы автоматически перебрасываются в список расширения. После сбора СЯ нужно перенести его в редактор таблиц и обработать. Важные плюсы программы: проверка на дубли, сортировка (алфавит, частотность, добавление), возможность дописать ключи вручную.

Пошаговая инструкция, как пользоваться сервисом, дана в статье: Яндекс. Вордстат (Wordstat): как собрать ключевые запросы?
Google Ads
Планировщик ключевых слов от Гугл, позволяющий бесплатно подобрать семантическое ядро онлайн. Сервис находит ключевики, основываясь на запросах пользователей поисковой системы Google. Для работы необходимо иметь аккаунт в Гугл.
Сервис предлагает:
- найти новые ключевые слова;
- посмотреть количество запросов и прогнозы.

Для сбора семантического ядра нужно ввести запрос, выбрав место расположения и язык. Программа показывает среднее число запросов в месяц и уровень конкуренции. Также есть сведения о показах объявлений и ставке для демонстрации объявления вверху страницы.
При необходимости, можно установить фильтр по конкуренции, средней позиции и другим критериям.

Также возможно запросить отчет (пошаговую инструкцию, как его сделать, показывает программа).

Чтобы изучить прогнозирование трафика, достаточно ввести запрос или набор ключей в окошко «Посмотрите количество запросов и прогнозы». Информация поможет определить эффективность СЯ при заданном бюджете и ставке.

К «минусам» сервиса можно отнести следующее: нет точной частотности (только средняя за месяц); не показывает зашифрованные ключи Яндекса и скрывает некоторые из Google. Зато определяет конкурентность и позволяет экспортировать ключевики в формате Excel.
SlovoEB
Это бесплатная версия программы Key Collector, которая обладает массой полезных функций:
- быстро собирает семантическое ядро из правой и левой колонок WordStat;
- выполняет пакетный сбор поисковых подсказок;
- определяет все виды частотности;
- собирает данные о сезонности;
- позволяет выполнить пакетный сбор слов и частотность из Rambler.Adstat;
- вычисляет KEI (коэффициент эффективности ключей).
Для пользования сервисом достаточно внести данные аккаунта в «Директ» (логин и пароль).
Хотите узнать больше – читайте статью: Slovoeb (Словоеб). Азы и инструкция по применению

Букварикс
Простая в использовании и бесплатная программа для сбора семантического ядра, база которой насчитывает более 2 млрд. запросов.
Отличается оперативной работой, а также полезными возможностями:
- поддерживает большой список слов-исключений (до 10 тыс.);
- позволяет создавать и применять списки слов непосредственно при формировании выборки;
- предлагает составлять списки слов умножением нескольких списков (Комбинатор);
- удаляет дубликаты ключевых слов;
- показывает частотность (но только «во всем мире», без выбора региона);
- анализирует домены (один или несколько, сравнивая СЯ ресурсов);
- экспортируется в формате.csv.
Единственный важный недостаток для установочной программы – большой «вес» (в заархивированном формате ≈ 28 Гб, в распакованном ≈ 100 Гб). Но есть альтернатива – подбор СЯ онлайн.

II. ПЛАТНО с помощью программ:
База Максима Пастухова
Русский сервис, в котором собрана база из более 1,6 миллиарда ключевиков с данными Yandex WordStat и Директ, а также английская, содержащая больше 600 млн слов. Работает онлайн, помогает не только в создании семантического ядра, но также в запуске рекламной кампании в Яндекс.Директ. Самым главным и немаловажным его недостатком можно смело назвать высокую стоимость.

Key Collector (Кей Коллектор)
Пожалуй, самый популярный и удобный инструмент для сбора семантического ядра.
Key Collector:
- собирает ключевики из правой и левой колонок WordStat Yandex;
- отсеивает» ненужные запросы с помощью опции «Стоп-слова»;
- ищет дубли и определяет сезонные ключевики;
- фильтрует ключи по частотности;
- выгружается в формате таблицы Excel;
- находит страницы, релевантные запросу;
- собирает статистику из: Google Analytics, AdWords и др.
Оценить, как Кей Коллектор выполняет сбор семантического ядра, можно бесплатно в демоверсии.

Rush Analytics
Сервис, с помощью которого можно выполнить сбор и кластеризацию семантического ядра.
Кроме этого, Rush Analytics:
- ищет подсказки в Youtube, Yandex и Google;
- предлагает удобный фильтр стоп-слов;
- проверяет индексацию;
- определяет частотность;
- проверяет позиции сайта для десктопов и мобильных;
- генерирует ТЗ на тексты и т. д.
Отличный инструмент, но платный: без демоверсии и лимитированных бесплатных проверок.

Мутаген
Программа собирает ключевые запросы из первых 30 сайтов в поисковой системе Yandex. Показывает частотность в месяц, конкурентность каждого поискового запроса и рекомендует использовать слова с показателем до 5 (т. к. для эффективного продвижения таких ключевиков достаточно качественного контента).
Полезная статья: 8 видов текстов для сайта – пишем правильно

Платная программа для сбора семантического ядра, но есть бесплатный лимит – 10 проверок в сутки (доступно после первого пополнения бюджета, хотя бы на 1 руб.). Открыта только для зарегистрированных пользователей.
Keyword Tool
Надежный сервис для создания семантического ядра, который:
- в бесплатной версии – собирает более 750 ключей для каждого запроса, используя подсказки Google, Youtube Bing, Amazon, eBay, App Store, Instagram;
- в платной – показывает частотность запросов, конкуренцию, стоимость в AdWords и динамику.
Программа не требует регистрации.

Кроме представленных инструментов, существует множество других сервисов для сбора семантического ядра сайта с детальными видеообзорами и примерами. Я остановилась на этих, т. к. считаю их самыми эффективными, простыми и удобными.
Вывод . Если есть возможность – желательно приобрести лицензии на пользование платными программами, так как у них функционал намного шире, чем у бесплатных аналогов. Но для простого сбора СЯ вполне подойдут и «открытые» сервисы.
Кластеризация семантического ядра
Готовое семантическое ядро, как правило, включает множество ключевиков (к примеру, по запросу «мягкая мебель» сервисы выдают несколько тысяч слов). Что делать дальше с таким огромным числом ключевых запросов?
Собранные ключи нужно:
I. Очистить от «мусора», дублей и «пустышек»
Запросы с нулевой частотностью, а также ошибками просто удаляем. Для устранения ключей с ненужными «хвостиками» советую использовать в Excel функцию «Сортировка и фильтр». Что может относиться к мусору? Например, для коммерческого сайта лишними будут такие слова, как: «скачать», «бесплатно» и др. Дубли также можно автоматически убрать в Эксель, воспользовавшись опцией «удалить дубликаты» (см. примеры ниже).
Убираем ключи с нулевой частотностью:

Удаляем ненужные «хвостики»:


Избавляемся от дубликатов:

II. Убрать высококонкурентные запросы
Если вы не хотите, чтобы «путь» в топ растянулся на годы – исключите ВК ключи. С такими ключевыми словами мало будет просто попасть на первые позиции в поисковой выдаче, но еще, что важнее и сложнее, – нужно постараться там удержаться.
Пример, как определить ВК-ключи через планировщик ключевых слов от Google (можно через фильтр оставить только НК и СК):


III. Выполнить разгруппировку семантического ядра
Сделать это можно двумя способами:
1. ПЛАТНО:
- KeyAssort – кластеризатор семантического ядра, который помогает создать структуру сайта и найти лидеров ниши. Работает на основе поисковиков Yandex и Google. Выполняет разгруппировку 10 тыс. запросов всего за пару минут. Оценить преимущества сервиса можно, скачав демо-версию.

- SEMparser выполняет автоматическую группировку ключей; создание структуры сайта; определение лидеров; генерацию ТЗ для копирайтеров; парсинг подсветки Yandex; определение геозависимости и «коммерческости» запросов, а также релевантности страниц. Кроме этого, сервис проверяет, насколько текст соответствует топу согласно SEO-параметрам. Как работает: собираете СЯ, сохраняете в формате.xls или.xlsx. Создаете на сервисе новый проект, выбираете регион, загружаете файл с запросами – и через несколько секунд получаете рассортированные по смысловым группам слова.

Кроме этих сервисов, могу посоветовать еще Rush Analytics, с которым уже познакомились выше, и Just-Magic .
Rush Analytics:

Just-Magic:

2. БЕСПЛАТНО:
- Вручную – с помощью Excel и функции «Сортировка и фильтр». Для этого: устанавливаем фильтр, вводим запрос для группы (к примеру, «купить», «цена»), выделяем список ключей цветом. Далее настраиваем опцию «Пользовательская сортировка» (в «Сортировка по цвету»), перейдя в «сортировать в пределах указанного диапазона». Последний штрих – добавляем названия группам.
Шаг 1

Шаг 2

Шаг 3

Шаг 4

Пример разгруппированного семантического ядра:

- SEOQUICK – бесплатная онлайн-программа для автоматической кластеризации семантического ядра. Чтобы «разбросать» ключи по группам, достаточно загрузить файл с запросами или добавить их вручную и минутку подождать. Инструмент работает быстро, определяя частотность и тип ключа. Дает возможность удалить лишние группы и экспортировать документ в формате Excel.

- Keyword Assistant . Сервис работает онлайн по принципу Excel-таблицы, т.е. раскидывать ключевики придется вручную, но занимает это гораздо меньше времени, чем работа в Эксель.

Как кластеризовать семантическое ядро и какие способы использовать – выбирать вам. Я считаю, что так, как нужно именно вам, можно сделать только вручную. Это долго, но эффективно.
После сбора и распределения семантического ядра по разделам можно приступать к написанию текстов для страниц.
Читайте по теме статью с примерами: Как правильно вписать ключевые слова в текст?
Общие правила для создания СЯ
Подводя итоги, важно добавить советы, которые помогут собрать правильное семантическое ядро:
|
СЯ следует составлять так, чтобы оно отвечало запросам как можно большего числа потенциальных клиентов. |
||
|
Семантика должна точно соответствовать тематике веб-проекта, т.е. фокусироваться следует только на целевых запросах. |
||
|
Важно, чтобы готовое семантическое ядро включало всего несколько высокочастотных ключей, остальная часть была заполнена средне- и низкочастотными. |
||
|
Следует регулярно расширять семантическое ядро для увеличения естественного трафика. |
И самое важное: все на сайте (от ключей до структуры) должно быть сделано «для людей»!
Вывод . Грамотно собранное семантическое ядро дает реальный шанс быстро продвинуть и удержать сайт на топовых позициях в поисковой выдаче.
Если сомневаетесь, что сможете собрать правильное СЯ, – лучше заказать семантическое ядро для сайта у профессионалов. Это сэкономит силы, время и принесет больше пользы.
Интересно также будет узнать: Как разместить и ускорить индексацию статьи? 5 секретов успеха
На этом все. Надеюсь, материал пригодится вам в работе. Буду благодарна, если поделитесь опытом и оставите комментарии. Спасибо за внимание! До новых онлайн-встреч!
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :

Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:

Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:
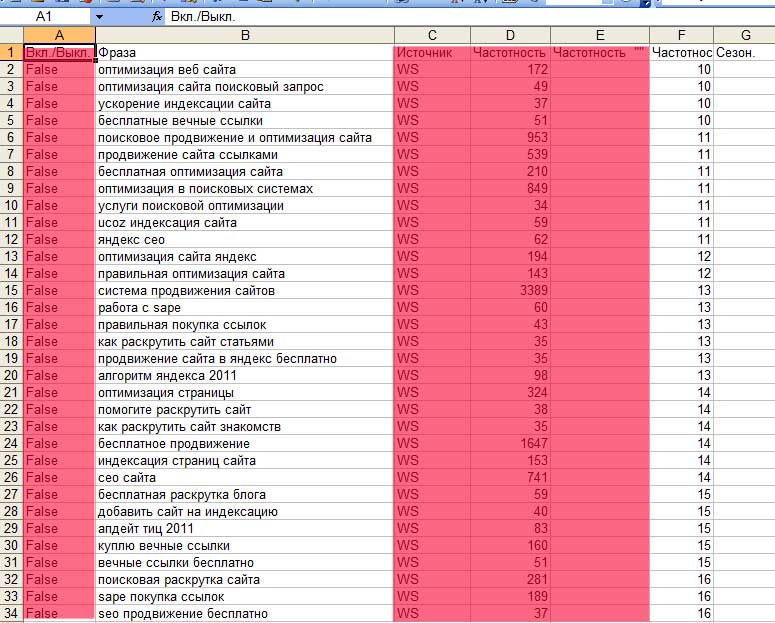
Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:


Затем проверяем стоимость получения одного перехода по нашим ключевым словам:

Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.

Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника
Михаил (Kashchey)
18.11.2015
Семантическое ядро сайта: что это такое? Сбор семантического ядра и анализ ключевых запросов
Что такое семантическое ядро (СЯ)? Перед тем, как я дам ответы, давайте разберёмся со смежными понятиями. Это нужно, чтобы мы говорили на одном языке. Итак:
Ключевой запрос (КЗ) – это фраза, которую вбивают в строку поиска Яндекса, Google и т. д.
Частотность запросов. Есть низкочастотные, среднечастотные и высокочастотные категории запросов (НЧ, СЧ, ВЧ)
Целевая аудитория (ЦА) . Те, кому интересны ваши услуги, товары или информация.
Что такое СЯ? СЯ – это совокупность ключевых запросов всех категорий, по которым на ваш сайт будет приходить ваша целевая аудитория. Как-то так. Второй вопрос, который нужно рассмотреть до того, как перейти к составлению семантического ядра, точнее к рассказу о том, как составить семантическое ядро, — это частотность ключевых запросов. Что это и как разделить запросы по частоте?
Разделить запросы по частоте несложно. Если ключ вбивают более 1000 раз в месяц, то это однозначно ВЧ. Если 100-1000, то это СЧ. Всё, что меньше 100 – это НЧ.
Внимание! В некоторых узких тематиках эти цифры не работают. То есть вам нужно найти самый высокочастотный запрос – это и будет ВЧ. Среднечастотные запросы будут между НЧ и ВЧ. Какие сервисы помогают узнать, сколько людей вбивают эту ключевую фразу ежемесячно? Ответ ищите в статье: (в этой статье вы найдёте информацию и о SEO-сервисах, которые помогают подобрать КЗ)
Теперь, когда я попытался объяснить, что есть что, приступаем к главному: к сбору семантического ядра.
Составление семантического ядра для сайта
Составить семантическое ядро не так просто, как кажется. Вам нужно учесть все возможные варианты НЧ и СЧ запросов. Для составления SEO-ядра лучше воспользоваться пециальными сервисами. Информацию о них можно найти по ссылке выше.
Как подбирать запросы? Представим, что вы создаёте сайт для любителей кошек. Как бы вы стали искать информацию о кошках? Чтобы вы написали в поиск? Первое, что придёт в голову. Например:
Кошка (ВЧ+) (кошки – это не отдельный запрос)
Сиамский кот (ВЧ)
Кошаки (СЧ)
Что едят домашние кошки (НЧ)
Частотность я проверял на сервисе wordstat.yandex.ru. Вот так:
Обратите внимание на кавычки. Они нужны, чтобы узнать, сколько людей вводили запрос в прямом вхождении. При составлении семантического нужно ориентироваться на прямые запросы и «хвосты». О «хвостах» можно почитать .
Надеюсь, что это понятно.
Найти все возможные тематически ключи – это муторная, кропотливая работа, которая отнимает много времени. Однако от качества сборки семантического ядра сайта зависит очень многое – успех дальнейшей SEO-оптимизации ресурса.
Что самое главное при составлении СЯ?
Самое важное при составлении семантического ядра – это грамотно структурировать все ключевые запросы. Это нужно, чтобы использовать составленное семантическое ядро максимально эффективно. И нет ничего лучше, чем таблица.
Вот удачный пример таблицы. К слову… таблицу лучше делать в программе Exel.
Итак, что мы видим? Мы видим грамотную структуру, по ней легко работать. Вы можете дополнить таблицу своими колонками, чтобы облегчить свою задачу.
Ваша задача найти как можно больше НЧ запросов с низкой конкуренцией и продвигать свой сайт по этим запросам. Как определить, что запрос низкоконкурентный? Если запрос НЧ, то в 80% случаев у него маленькая конкуренция. Проверить уровень конкуренции можно и в поисковике. Вот так:
Результат: 43 миллиона ответов. Конкуренция для темы кошек будет низкая. Для других тем нужно ориентироваться на другие цифры. Например, КЗ «копирайтер» — это ВЧ ключ с 2 миллионами ответов, и он имеет высокую конкуренцию.
В статьи под НЧ запросы автоматически будут вписываться ВЧ запросы – это нормально. Лучше всего писать одну статью на один КЗ, подбирать к ней картинку и прогонять её по группам в социальных сетях + продвигать её статьями со ссылкой, но это долго и накладно. Поэтому в статью включают 2-3 ключа – это позволяет сократить расходы на статьи.
Статья не ответила на ваш вопрос? Так задайте его в комментариях!
P.S. мне будет приятно.
Быстрая навигация по этой странице:
Как и практически все другие вебмастеры, я составляю семантическое ядро с помощью программы KeyCollector — это безусловно лучшая программа для составления семантического ядра. Как ей пользоваться — это тема для отдельной статьи, хотя и в Интернете полно информации на этот счет — рекомендую, к примеру, мануал от Дмитрия Сидаша (sidash.ru).
Поскольку поставлен вопрос о примере составления ядра — привожу пример.
Список ключей
Предположим, у нас сайт посвящен британским кошкам. Вбиваю в «Список фраз» словосочетание «британская кошка» и нажимаю на кнопку «Парсить».
Получаю длинный список фраз, который будет начинаться со следующих фраз (приведена фраза и частнотность):
Британские кошки 75553 британские кошки фото 12421 британская вислоухая кошка 7273 питомник британских кошек 5545 кошки британской породы 4763 британская короткошерстная кошка 3571 окрасы британских кошек 3474 британские кошки цена 2461 кошка голубая британская 2302 британская вислоухая кошка фото 2224 вязка британских кошек 1888 британские кошки характер 1394 куплю британскую кошку 1179 британские кошки купить 1179 длинношерстная британская кошка 1083 беременность британской кошки 974 кошка британская шиншилла 969 кошки британской породы фото 953 питомник британских кошек москва 886 окрас британских кошек фото 882 британские кошки уход 855 британская короткошерстная кошка фото 840 шотландские и британские кошки 763 имена британских кошек 762 кошка британская голубая фото 723 фото британской голубой кошки 723 британская кошка черная 699 чем кормить британских кошек 678
Сам список намного больше, я только привел его начало.
Группировка ключей
Исходя из этого списка, у меня на сайте будут статьи про разновидности кошек (вислоухая, голубая, короткошерстная, длинношерстная), будет статья про беременность этих животных, про то, чем их кормить, про имена и так далее по списку.
Под каждую статью берется один основной такой запрос (=тема статьи). Впрочем, только одним запросом статья не исчерпывается — в нее также добавляются другие подходящие по смыслу запросы, а также разные вариации и словоформы основного запроса, которые можно найти в Кей Коллекторе ниже по списку.
Например, со словом «вислоухая» имеются следующие ключи:
Британская вислоухая кошка 7273 британская вислоухая кошка фото 2224 британская вислоухая кошка цена 513 порода кошек британская вислоухая 418 британская голубая вислоухая кошка 224 шотландские вислоухие и британские кошки 190 кошки британской породы вислоухие фото 169 британская вислоухая кошка фото цена 160 британская вислоухая кошка купить 156 британская вислоухая голубая кошка фото 129 британские вислоухие кошки характер 112 британская вислоухая кошка уход 112 вязка британских вислоухих кошек 98 британская короткошерстная вислоухая кошка 83 окрас британских вислоухих кошек 79
Чтобы не было переспама (а переспам может быть и по совокупности использования слишком большого количества ключей в тексте, в заголовке, в и т.д.), я бы не стал брать их все с включением основного запроса, но отдельные слова из них имеет смысл употребить в статье (фото, купить, характер, уход и т.д.) для того, чтобы статья лучше ранжировалась по большому количеству низко-частотных запросов.
Таким образом, у нас под статью про вислоухих кошек сформируется группа ключевых слов, которые мы употребим в статье. Точно также сформируются и группы ключевиков под другие статьи — вот и ответ на вопрос о том, как создать семантическое ядро сайта.
Частотность и конкуренция
Еще есть немаловажный момент, связанный с точной частотностью и конкуренцией — их обязательно нужно собрать в Key Collector. Для этого нужно выделить все запросы галочками и на вкладке «Частотности Yandex.Wordstat» нажать кнопку «Собрать частотности «!» — будет показана точная частнотность каждой фразы (т.е. именно с таким порядком слов и в таком падеже), это намного более точный показатель, чем общая частотность.
Для проверки конкуренции в том же Key Collector нужно нажать кнопку «Получить данные для ПС Яндекс» (или для Google), далее нажать «Рассчитать KEI по имеющимся данным». В результате программа соберет, сколько главных страниц по данному запросу находится в ТОП-10 (чем больше — тем сложнее туда пробиться) и сколько страниц в ТОП-10 содержат такой title (аналогично, чем больше — тем сложнее пробиться в топ).
Дальше нужно действовать исходя из того, какая у нас стратегия. Если мы хотим создать всеобъемлющий сайт про кошек, то нам не так важна точная частотность и конкуренция. Если же нам нужно только опубликовать несколько статей — то берем запросы, у которых самая высокая частотность и при этом самая низкая конкуренция, и на их основании пишем статьи.
В данный момент для поискового продвижения максимально важную роль играют такие факторы как контент и структура. Однако, каким образом понять о чем писать текст, какие разделы и страницы создать на сайте? В дополнении к этому вам нужно точно узнать чем именно интересуется целевой посетитель вашего ресурса. Чтобы ответить на все эти вопросы нужно собрать семантическое ядро.
Семантическое ядро — список слов или фраз, полностью отражающих тематику вашего сайта.
В статье я расскажу как его подобрать, почистить и разбить на структуру. Результатом будет являться законченная структура с запросами кластеризованными по страницам.
Вот пример ядра запросов разбитого на структуру:

Под кластеризацией я понимаю разбивку ваших поисковых запросов на отдельные страницы. Данный способ будет актуален как для продвижения в ПС Яндекса, так и Гугла. В статье я опишу совершенно бесплатный способ создания семантического ядра, однако буду показывать и варианты с различными платными сервисами.
Прочитав статью, вы научитесь
- Выбирать правильные запросы под вашу тематику
- Собирать максимально полное ядро фраз
- Чистить от неинтересных запросов
- Группировать и создавать структуру
Собрав семантическое ядро вы сможете
- Создать осмысленную структуру на сайте
- Создать многоуровневое меню
- Наполнять страницы текстами и писать на них метаописания и title
- Собирать позиции вашего сайта по запросам из поисковых систем
Сбор и кластеризация семантического ядра
Правильное составление для Google и Яндекс начинается с определения основных ключевых фраз вашей тематики. Для примера, я буду демонстрировать его составление на выдуманном интернет-магазине одежды. Есть три пути по сбору семантического ядра:
- Ручной.
Используя сервис Яндекс Wordstat , вы вводите ваши ключевые слова и руками выбираете необходимые вам фразы. Данный способ достаточно быстрый, если вам нужно собрать ключи на одну страницу, однако, есть два минуса.
- Точность метода «хромает». Вы всегда можете упустить какие-либо важные слова, если будете использовать этот метод.
- Вы не сможете собрать семантическое ядро на большой интернет-магазин, хотя для упрощения можно использовать плагин Yandex Wordstat Assistant — проблему это не решит.
- Полуавтоматический.
В этом методе я предполагаю использование программы для сбора ядра и дальнейшее ручная разбивка на разделы, подразделы, страницы и т.п. Данный метод составления и кластеризации семантического ядра по моему мнению наиболее эффективный т.к. имеет ряд плюсов:
- Максимальный охват всей тематики.
- Качественная разбивка
- Автоматический. В наше время существует несколько сервисов, которые предлагают полностью автоматический сбор ядра либо же кластеризацию ваших запросов. Полностью автоматический вариант — не рекомендую к использованию, т.к. качество сбора и кластеризации семантического ядра на данный момент довольно низкая. Автоматическая кластеризация запросов — набирает популярность и имеет место быть, но вам необходимо все-равно будет объединять какие-то страницы руками, т.к. система не дает идеального готового решения. И по моему мнению вы просто запутаетесь и не сможете погрузиться в проект.
Для составления и кластеризации полноценного правильного семантического ядра на любой проект в 90% случаев я использую полуавтоматический метод.
Итак, чтобы нам нужно выполнить следующие шаги:
- Подбор запросов для тематики
- Сбор ядра по запросов
- Чистка от нецелевых запросов
- Кластеризация (разбиваем фразы на структуру)
Пример подбора семантического ядра и группировки на структуру я показывал выше. Напоминаю, что у нас интернет-магазин одежды, начнем же разбирать 1 пункт.
1. Подбор фраз для вашей тематики
На данном этапе нам понадобиться инструмент Яндекс Вордстат , ваши конкуренты и логика. В этом шаге важно собрать список фраз, которые являются тематическими высокочастотными запросами.
Как подбирать запросы для сбора семантики с Yandex Wordstat
Заходите на сервис, выбираете нужный вам город(а)/регион(ы), вбиваете самые «жирные» по вашему мнению запросы и смотрите на правую колонку. Там вы найдете нужные вам тематические слова, как на другие разделы, так и частотные синонимы к вписанной фразе.

Как подбирать запросы перед составлением семантического ядра с помощью конкурентов
Впишите в поисковой системе самый популярные запросы и выберите один из самых популярных сайтов, многие из которых вы, скорее всего, и так знаете.

Обратите внимание на основные разделы и сохраняйте себе необходимые вам фразы.
На данном этапе важно сделать правильно: максимально охватить всевозможные слова из вашей тематики и ничего не упустить, тогда ваше семантическое ядро будет максимально полным.
Применимо к нашему примеру, нам нужно составить список из следующие фраз/ключевых слов:
- Одежда
- Обувь
- Сапоги
- Платья
- Футболки
- Нижнее белье
- Шорты
Какие фразы вписывать бессмысленно : женская одежда, купить обувь, платье на выпускной и т.п. Почему? — Данные фразы являются «хвостами» запросов «одежда», «обувь», «платья» и будут добавлены в семантическое ядро автоматически на 2 этапе сбора. Т.е. вы можете их добавлять, но это будет бессмысленной двойной работой.
Какие ключи вписывать нужно? «полусапоги», «сапожки» не одно и тоже, что и «сапоги». Важна именно словоформа, а не то однокоренные это слова или нет.
У кого-то список ключевых фраз будет длинный, а у кого он состоит из одного слова — не пугайтесь. Например, интернет-магазину дверей для составления семантического ядра вполне возможно достаточно слова «двери».
И так, в конце данного шага у нас должен быть подобный список.

2. Сбор запросов для семантического ядра
Для правильного полноценного сбора нам необходимо программа. Я буду показывать пример одновременно на двух программах:
- На платной — KeyCollector. Для тех у кого есть, либо кто хочет купить.
- На бесплатной — Slovoeb. Бесплатная программа для тех, кто не готов тратиться.
Открываем программу

Создаем новый проект и назовем его, например, Mysite

Теперь для дальнейшего сбора семантического ядра нам нужно сделать несколько вещей:
Создать новый аккаунт на Яндекс почте (старый не рекомендуется использовать по причине того, что его могут забанить за множество запросов). Итак, вы создали аккаунт, например [email protected] с паролем super2018. Теперь вам нужно указать этот аккаунт в настройках как ivan.ivanov:super2018 и нажать внизу кнопку «сохранить изменения». Подробнее — на скриншотах.

Выбираем регион для составления семантического ядра. Нужно выбрать только те регионы, в которых вы собираетесь продвигаться и нажать сохранить. От этого будет зависеть частотность запросов и попадут ли они в сбор в принципе.

Все настройки завершены, осталось добавить наш заготовленный на первом шаге список ключевых фраз и нажать кнопку «начать сбор» семантического ядра.

Процесс полностью автоматический и достаточно долгий. Можете пока сделать кофе, а если тематика широкая, например, подобно той, что мы собираем — то это на несколько часов 😉
Как только все фразы соберутся вы увидите нечто подобное:

И на этом этап закончен — приступаем к следующему шагу
3. Чистка семантического ядра
Вначале нам нужно удалить запросы, которые нам не интересны (нецелевые):
- Связанные с другим брендом, например, «глория джинс», «экко»
- Информационные запросы, например, «ношу сапоги», «размер джинсов»
- Схожие по тематике, но не относящиеся к вашему бизнесу, например, «б у одежда», «одежда оптом»
- Запросы, никак не связанные с тематикой, например, «симс платья», «кот в сапогах» (таких запросов после подбора семантическом ядре бывает достаточно много)
- Запросы из других регионов, метро, округов, улиц (неважно по какому региону вы собирали запросы — другой регион все-равно попадается)
Чистку нужно проводить вручную следующим образом:

Вводим слово, нажимаем «Enter», если в нашем созданном семантическом ядре находит именно те фразы что нам нужно, выделяем найденное и нажимаем удалить.
Рекомендую вводить слово не целиком, а используя конструкцию без предлогов и окончаний, т.е. если мы напишем слово «глори», то найдет фразы «купить в глория джинс» и «купить в глории джинс». При написании «глория» — «глории» не было бы найдено.
Таким образом вам нужно пройти по всем пунктам и удалить из семантического ядра ненужные вам запросы. Это может занять значительное время, и, возможно, получится так, что вы удалите большую часть собранных запросов, но результатом будет полноценный чистый и правильный список всевозможных продвигаемых запросов для вашего сайта.
Выгрузите теперь все ваши запросы в excel

Также вы можете массово удалить из семантики нецелевые запросы, при условии, что у вас есть список. Можно это сделать при помощи стоп-слов и это легко сделать для типовой группы слов с городами, метро, улицами. Список таких слов, которыми я пользуюсь вы сможете скачать внизу страницы.
4. Кластеризация семантического ядра
Это самая важная и интересная часть — необходимо разделить наши запросы на страницы и разделы, которые в совокупности создадут структуру вашего сайта. Немного теории — чем руководствоваться при разделении запросов:
- Конкуренты . Вы можете обратить внимание на то, как кластеризовано семантическое ядро у ваших конкурентов из ТОПа и поступать аналогичным образом, по крайней мере с основными разделами. А также смотреть, какие страницы находятся в выдаче по низкочастотным запросам. Например, если вы не уверены «делать или нет» отдельный раздел для запроса «красные кожаные юбки», то вбейте фразу в поисковую систему и посмотрите выдачу. Если в выдаче содержаться ресурсы, где есть такие разделы, значит, имеет смысл сделать отдельную страницу.
- Логика . Всю группировку семантического ядра делайте используя логику: структура должна быть понятна и представлять у вас в голове структурированное дерево страниц с категориями и подкатегориями.
И еще пара советов:
- На страницу не рекомендуется ставить менее 3 запросов.
- Не делайте слишком много уровней вложенности, старайтесь делать так, чтобы их было 3-4 (сайт.ру/категория/подкатегория/под-подкатегория)
- Не делайте длинные URL, если у вас много уровней вложенности при кластеризации семантического ядра, старайтесь сокращать url высоких по иерархии категорий, т.е. вместо «vash-site.ru/zhenskaya-odezhda/palto-dlya-zhenshin/krasnoe-palto» делайте «vash-site.ru/zhenshinam/palto/krasnoe»
Теперь к практике
Кластеризация ядра на примере
Для начала разнесем все запросы по основным категориям. Посмотрев по логике конкурентов — основными категориями для магазина одежды будут являться: мужская одежда, женская одежда, детская одежда, а также куча других категорий, которые не привязаны к полу/возрасту, такие как просто «обувь», «верхняя одежда».
Группируем семантическое ядро это при помощи Excel. Открываем наш файл и действуем:
- Разбиваем на основные разделы
- Берем один раздел и разбиваем его на подразделы
Я покажу на примере одного раздела — мужская одежда и его подраздела. Для того, чтобы отделить одни ключи от других нужно выделить весь лист и нажать условное форматирование->правила выделения ячеек->текст содержит

Теперь в открывшемся окне пишем «муж» и нажимаем энтер.

Теперь все наши ключи по мужской одежде выделены. Достаточно воспользоваться фильтром, чтобы отделить выделенные ключи от всего остального нашего собранного семантического ядра.
Итак включим фильтр: нужно выделить столбик с запросами и нажать сортировка и фильтр->фильтр

И теперь отсортируем

Создайте отдельный лист. Вырезайте выделенные строки и вставляйте их туда. Этим способом вам нужно будет в дальнейшем и разбивать ядро.
Измените название этого листа на «Мужская одежда», лист, где все остальное семантическое ядро назовите «Все запросы». Затем создайте еще один лист, назовите его «Структура» и поставьте его самым первым. На странице со структурой создавайте дерево. У вас должно получится так:

Теперь нам нужно разделить большой раздел мужской одежды на подразделы и под-подразделы.
Для удобства использования и переходов по вашему кластеризованному семантическому ядру поставьте ссылки со структуры на соответствующие листы. Для этого кликните правой кнопкой мыши на нужный пункт в структуре и делайте как на скриншоте.

И теперь методично руками нужно разделять запросы, попутно удаляя то, что, возможно, не удалось заметить и удалить на этапе очистки ядра. В конечном счете благодаря кластеризации семантического ядра у вас должна получится структура похожая на вот эту:


Итак. Что мы научились делать:
- Выбирать нужные нам запросы для сбора семантического ядра
- Собирать все-возможные фразы для этих запросов
- Чистить от «мусора»
- Кластеризовать и создавать структуру
Что благодаря созданию такого кластеризованного семантического ядра вы можете делать дальше:
- Создавать структуру на сайте
- Создавать меню
- Писать тексты, метаописания, тайтлы
- Собирать позиции для отслеживания динамики по запросам
Теперь немного о программах и сервисах
Программы для сбора семантического ядра
Здесь я опишу не только программы, но и плагины и онлайн сервисы, которые использую
- Yandex Wordstat Assistant — плагин, благодаря которому, удобно подбирать запросы из вордстата. Отлично подходит для быстрого составления ядра на маленький сайт или на 1 страницу.
- Кейколлектор (словоеб — бесплатная версия) — полноценная программа для кластеризации и создания семантического ядра. Пользуется большой популярностью. Огромное количество функционала помимо основного направления: Подбор ключей с кучи других систем, возможность автокластеризации, сбор позиций в Яндексе и Гугле и многое другое.
- Just-magic — многофункциональный онлайн-сервис для составления ядра, авторазбивки, проверка качества текстов и также другие функции. Сервис условно-бесплатный, для полноценной работы нужно платить абонентскую плату.
Спасибо за то, что прочитали статью. Благодаря данному пошаговому мануалу вы сможете составить семантическое ядро вашего сайта для продвижения в Яндексе и Гугле. Если у вас остались какие-либо вопросы — задавайте в комментариях. Ниже — бонусы.
Google аккаунт обход FRP после сброса на Андроид
Выбираем недорогое сетевое хранилище для дома и не только
Взлом систем шифрования жестких дисков путем «холодной перезагрузки
Настраиваем графику в WOT
В мире четыре миллиарда интернет-пользователей